Introduction à la théorie des valeurs extrêmes : calcul d’une canicule centennale avec Python
Pendant la canicule de juillet 2022, la chaleur a mis en défaut la climatisation des datacenters de 2 hôpitaux londoniens privant l’ensemble du personnel — plus de 23.000 médecins, infirmiers, etc. — de l’accès aux dossiers des patients ou aux résultats d’examen. La cause de cet accident : la température extérieure a dépassé le niveau maximal pour lequel les systèmes de refroidissement étaient conçus.
C’est que déterminer la température maximale qui peut être rencontrée à un endroit est un exercice plus compliqué qu’il n’y parait…
Dans ce tutoriel, nous allons essayer de comprendre pourquoi puis voir quelles est la principale méthode employée aujourd’hui pour déterminer la probabilité et la sévérité d’événements extrêmes à partir de données limitées.
Température maximale : une approche naïve
A priori, la façon la plus simple de savoir quelle est la température maximale que l’on peut rencontrer à un endroit est de regarder les températures les plus élevées qui ont été atteintes dans le passé.
Pour cette démonstration, nous allons nous appuyer sur les températures maximales enregistrée à Orly au cours des 30 dernières années. Cette série est basée sur les données du Global Historical Climatology Network, mais pour gagner du temps nous avons préparé un jeu de donnée au format csv que vous pouvez utiliser pour reproduire ce tutoriel.
Commençons par ouvrir l’ouvrir et afficher les mesures :
Voici le résultat :

Une première approche peut consister à faire des statistiques sur cette série : isolons les mois d’été et regardons quel est le dernier décile et le dernier centile de température :
Le dernier décile de température est de 30.9°C et le dernier centile est de 36.6°C. Si le climat de demain est comparable à celui des 30 dernières années, on peut s’attendre à ce que le premier seuil soit dépassé environ une dizaine de jours par an en moyenne et le second à peu près une fois par été en moyenne.
Ce sont des indications intéressantes mais seulement si vous pouvez accepter que la température limite soit dépassée régulièrement. Si vous dimensionnez un système critique — la climatisation d’un hôpital ou un système de refroidissement industriel dont l’arrêt peut couter des millions d’euros… — ces valeurs sont à peu près inutiles.
Les événements extrêmes sont rares…
Pourquoi alors ne pas prendre un quantile plus élevé ? par exemple dernier millile, qui n’a été atteint que 0.01% des jours sur la période 1991–2020 ?
D’abord parce que ce quantile va être calculé sur seulement 2 ou 3 jours selon la méthode utilisée. Avec un échantillon aussi réduit rien ne vous prouve que la valeur obtenue est représentative du climat local : le résultat peut être entièrement déterminé par un bref pic de chaleur qui a très peu de chance de se reproduire ou, au contraire, votre série peut ne pas contenir d’exemples d’événement correspondant à cette probabilité.
La série d’Orly donne plusieurs exemples de ces limites :
- Si on calcule le dernier millile avant 2003, on obtient 37.2°C. Valeur largement dépassée pendant la canicule de 2003 avec un maximum de 40°C.
- Si on refait le calcul avant 2019, on obtient 39.4°C. Valeur là encore dépassée pendant la canicule de 2019 avec un record de 41.9°C.
D’ailleurs, même si par chance il était représentatif, sur une série de 30 ans, le dernier millile correspond approximativement à un événement décennal, c’est-à-dire qui va se produire en moyenne tous les 10 ans ou, pour le dire autrement, qui a une probabilité de 10% de se produire chaque année. La probabilité de dépassement est donc loin d’être négligeable et elle reste beaucoup trop élevée pour de nombreuses applications :
Les systèmes critiques sont plutôt dimensionnés sur un événement centennal (probabilité d’occurrence de 1% par an), millénal (0.1% par an) voire, par exemple dans l’industrie nucléaire, décamillénal (0.01% par an).
Les événements extrêmes, par définition, sont rares. C’est bien le problème : il est pratiquement impossible d’obtenir une série de données assez longue pour les évaluer avec précision.
Par exemple, si vous voulez déterminer un événement centennal, même un siècle d’observations ne suffit pas : la probabilité qu’il contienne exactement un événement centennal est seulement de 37.0%, à peine moins que le probabilité qu’il n’en contiennent aucun (36.7%). Et il y a aussi une probabilité de 26.3% que la série contienne deux événements centennaux ou plus.
Pour pouvoir calculer un événement centennal avec un niveau de confiance correct, il faudrait au moins de l’ordre de 300 années de données. Sans même parler de la fiabilité des mesures ou de l’évolution du climat sur une période aussi longue, la plus ancienne série de température journalière démarre en 1772… soit il y a 250 ans.
Théorie des valeurs extrêmes
En réalité, les méthodes classiques de statistiques et de probabilité sont destinées à étudier le probable. Or, dans notre cas, c’est l’improbable que l’on souhaite quantifier.
C’est ici qu’entre en scène une branche des statistiques spécialisée dans l’étude de ce type d’événements : la théorie des valeurs extrêmes (extreme value theory ou extreme value analysis en anglais).
Mise au point au milieu du XXe siècle, l’analyse des valeurs extrêmes a été largement utilisée en hydrologie, en ingénierie ou en finance avant de trouver dans les années 2000 un nouveau champ d’application dans la climatologie.
Le principe général de l’analyse consiste à isoler dans une série d’observations les valeurs extrêmes puis à les utiliser pour construire la queue de la distribution de probabilité. Cette distribution servira ensuite à calculer la probabilité d’événements trop rares pour être représentés de façon fiable dans l’échantillon initial.
identification des extrêmes et distribution théorique
Reprenons notre série de température et commençons par identifier ses valeurs extrêmes. Il existe deux approches pour cela :
- Par bloc : on découpe l’échantillon en blocs (souvent une année) et on prend la valeur maximale de chaque bloc
- Par seuil : on prend les valeurs supérieures à un certain seuil en respectant une distance minimale entre deux valeurs pour assurer leur indépendance (par exemple si le seuil est dépassé plusieurs fois pendant une même vague de chaleur on ne prend que la valeur la plus élevée).
Dans les deux cas, il faut s’assurer que les extrêmes sélectionnés correspondent bien à des phénomènes homogènes. Par exemple dans les climats qui ont deux saisons chaudes, il faudra faire l’étude de chaque saison séparément car les extrêmes peuvent avoir des distributions différentes dans les deux cas. De la même façon, si on étudie la vitesse du vent, il faudra séparer tempêtes hivernales et ouragans.
La méthode par bloc est plus simple à mettre en œuvre. Nous allons l’utiliser avec un bloc d’un an :
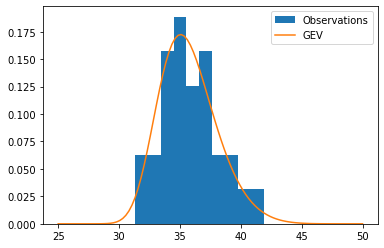
On obtient la répartition suivante :

D’après le théorème de Fisher-Tippett-Gnedenko, cette distribution normalisée doit converger aux limites vers la loi des valeurs extrêmes généralisée (generalized extreme values ou GEV en anglais). D’autres distributions théoriques sont parfois utilisées comme les lois de Weibull, de Gumbel ou de Fréchet mais il ne s’agit que de cas particuliers de la GEV.
Nous allons donc ajuster cette distribution théorique sur celle de nos températures extrêmes.
Il existe plusieurs méthodes pour ajuster la GEV et elles peuvent donner des résultats un peu différents. Pour le moment, nous allons utiliser la méthode par défaut de scipy qui est la méthode du maximum de vraisemblance.
On obtient le résultat suivant :
Calcul des temps de retour
Représentons maintenant l’histogramme cumulé des extrêmes et la fonction de répartition de la GEV :

Cette représentation permet de mieux comprendre l’interprétation de la fonction de répartition : c’est est la probabilité annuelle qu’une température ne soit pas atteinte. Par exemple la probabilité de ne pas atteindre 30 est à peu près zéro alors que celle de ne pas atteindre 40°C est très élevée.
Dit autrement, la fréquence moyenne d’un événement est 1 — CDF, où CDF est la fonction de répartition de la distribution. Comme la période est l’inverse de la fréquence, le temps de retour d’un événement est 1 / (1 — CDF).
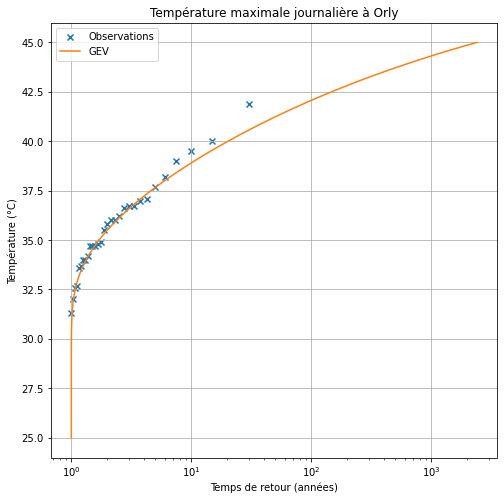
On peut donc représenter la température atteinte en fonction du temps de retour :
Le graphique obtenu permet d’estimer le temps de retour pour différentes températures. Par exemple, 40°C correspond approximativement à un temps de retour de 20 ans :
On peut maintenant calculer la température atteinte pour différents temps de retour.
Pour cela nous allons utiliser gev.isf() qui donne directement l’inverse de la fonction de survie, c’est-à-dire 1/(1 — CDF).
On obtient les résultats suivants :
- Temps de retour de 5 ans : 37.7°C
- Temps de retour de 10 ans : 38.9°C
- Temps de retour de 20 ans : 40.0°C
- Temps de retour de 50 ans : 41.2°C
- Temps de retour de 100 ans : 42.1°C
Quelques recommandations de prudence…
La méthode que l’on vient de détailler est largement utilisée pour l’évaluation des risques climatiques physiques dans l’industrie, l’assurance ou l’aménagement. Cependant les résultats doivent être interprétés avec prudence.
D’abord on considère généralement que cette méthode permet d’évaluer les extrêmes avec un niveau de confiance acceptable jusqu’à environ 3 fois la taille de l’échantillon initial dans un climat stationnaire. C’est-à-dire qu’un échantillon de 30 années est tout juste suffisant pour calculer l’événement centennal. Au-delà, la qualité des résultats obtenus est très hypothétique.
Lorsqu’il existe assez de données, on pourrait prendre un historique plus important mais dans ce cas c’est l’hypothèse de stationnarité qui ne serait plus vérifiée. Faute de mieux — beaucoup d’analyses statistiques nécessitent des séries longues — on admet que le climat est à peu près stable sur 30 ans. C’est discutable : sous l’effet de nos émissions de gaz à effet de serre, le climat change rapidement et même sur 30 années cette évolution peut l’emporter sur la variabilité naturelle. Sur 50 ou 100 ans, c’est sur…
C’est une autre limite de ces extrapolations : calculer un événement centennal, ce n’est pas savoir ce qu’il va se passer sur le siècle à venir.
D’abord parce qu’un temps de retour ne signifie pas que l’événement doit se produire exactement une fois par période : il peut très bien ne pas se produire ou se produire plusieurs fois. Il est préférable d’interpréter les temps de retour comme une probabilité annuelle : par exemple un temps de retour de 10 ans signifie que la probabilité annuelle est de 10%.
Ensuite parce que ce calcul est fait pour le climat des 30 dernières années que, encore une fois faute de mieux, on considère représentatif du climat présent. Plus on s’éloigne dans le temps, moins cette hypothèse est valable. Il est évident que la vague de chaleur centennale de 2100, ou même de 2050, n’aura pas grand chose à voir avec celle que l’on a calculée sur 1991-2020. Pour évaluer les temps de retour sur un horizon supérieur à une ou deux décennies, il est sans doute préférable de s’appuyer sur des simulations du climat futur plutôt que sur des données passées.
Dernière remarque : l’extrapolation est réalisée avec un modèle statistique, pas un modèle physique. Elle peut parfois donner des valeurs supérieures aux limites physiques — lorsqu’ils en existent. Une relecture experte reste donc dans tous les cas nécessaire.
👋Et puisqu’on en parle : vous avez besoin d’un expert ? Avec plus de 50.000 diagnostics fournis en 2022, Callendar est la référence française dans le développement de solutions accessibles pour l’évaluation des risques climatiques à l’échelle locale.
Que ce soit pour un site ou pour un portefeuille de milliers d’actifs, pour un projet ponctuel ou pour mettre en place des outils sur-mesure, pour évaluer les risques présents ou tout au long du XXIe siècle… Nous avons les outils pour vous aider. Contactez-nous pour discuter de votre projet !
